A Quick Guide to Supervised and Unsupervised Learning Models
Posted on: June 6, 2022
Post Category: Data

One of the first things you encounter when learning statistical learning methods are the two main types: supervised learning and unsupervised learning.
This post is for anyone who may be confused about the differences between these two main types. It will go through (hopefully) simple and high-level definitions and an illustrative example of each.
Note: granted, there are other types including, but not limited to, reinforcement learning and semi-supervised learning. I won’t be covering them in this post, but perhaps I will in the future.
Definitions
A supervised learning model is a statistical learning model that is developed using a dataset that contains a response variable (in conjunction with the predictors variables), where the response is what we want to predict. For a supervised learning model, a dataset is typically split into a training set and test set. The training set would be used to gain estimates of the parameters of the model – to “learn” the patterns of the observed data – while the test set is used to measure the accuracy of the model – by comparing distances between the actual values and the values predicted by the model.
Examples of supervised learning models include:
- Regressors e.g. simple and multiple linear regression
- Classifiers e.g. k-nearest neighbours (KNN), support vector machines (SVM) and logistic regression
- Tree-based classifiers: decision trees and random forest
On the other hand, an unsupervised learning model is one that is developed using a dataset that does not contain a response variable (i.e. only the predictor variables or covariates are present in the data). For an unsupervised learning model, since there is no response variable, there is no way of directly computing the accuracy.
A common example of an unsupervised learning model is clustering.
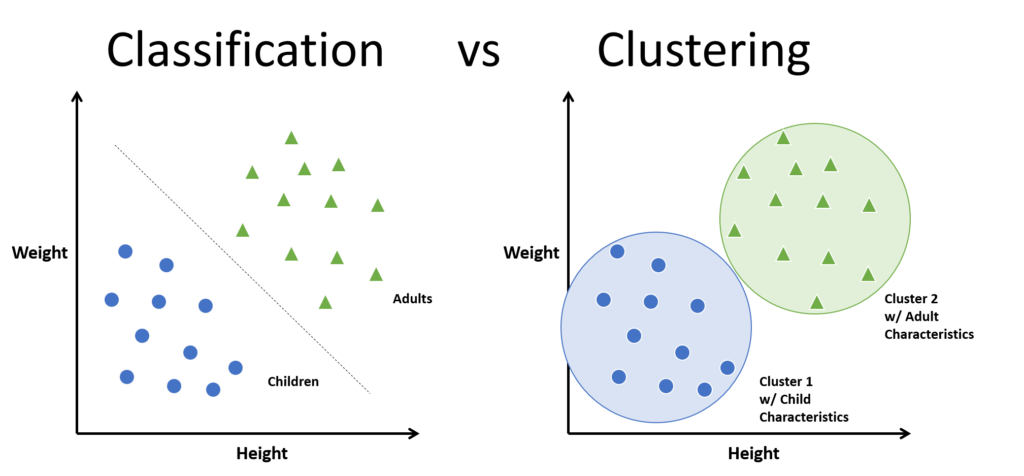
The way I like to distinguish between these two main types is as follows:
- The accuracy of a supervised learning model is “supervised” through a response variable
- The accuracy of an unsupervised learning model is not supervised
An illustrative example
For our first example, suppose you work for a bank and you are given data on borrowers. For each borrower, you are given their credit score, income, data on other borrowings, and whether or not the borrower has defaulted on a loan given by the bank. You are asked to create an algorithm that predicts whether or not someone will default on a loan.
Here, the response (i.e. what you want to predict) is already in your data, so you would use a supervised learning model.
For our second example, suppose you work as an analyst at a supermarket and you are given data on customers. For each customer, you are given the amount they spend, the frequency at which they come into the store, and the number of discounts they redeem. You are asked to segment the market and develop a marketing strategy for the different segments.
Here, the customers are not labelled with the marketing segment they belong to, so you would use an unsupervised learning model, otherwise you would go for a supervised learning model.

About the author
Jason Khu is the creator of Data & Development Deep Dives and currently a Data Analyst at Quantium.